Indexing
Establishing an Initial Query Index In this segment, we’ll generate a query index within the root folder, set to index all the documents present in our backend system.
Once we configure your fstab.yaml with a mount point directed towards your SharePoint site or Google Drive, proceed to the root folder.
Create raw_index tab within query-index Google Sheet inside root folder. Create columns having columns title, image, description, and lastModified as shown below:
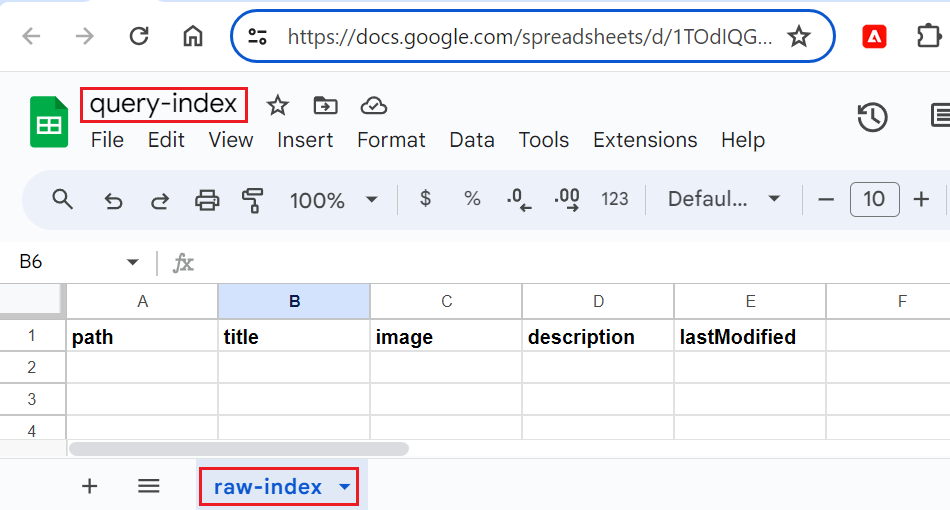
Below is the query-index Google Sheet got created in root folder:
On publish pages will by default get index and on unpublish page will get remove from index.
We can achieve same with robots.txt setting metadata property to noindex to automatically omit page from indexing.
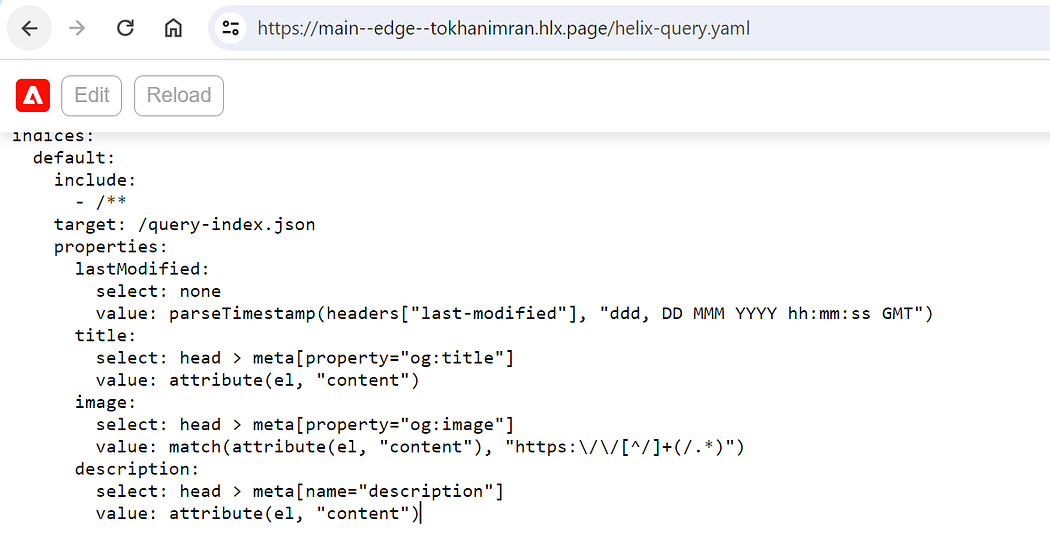
helix-query.yaml file allow us see configuration got added as part of raw_index tab within query_index Google Sheet.
Post activating our index, preview the spreadsheet using the sidekick. This will create an index configuration from the spreadsheet that can be viewed at the following location:
‘https://main–edge–tokhanimran.hlx.page/helix-query.yaml’
Checking Our Index
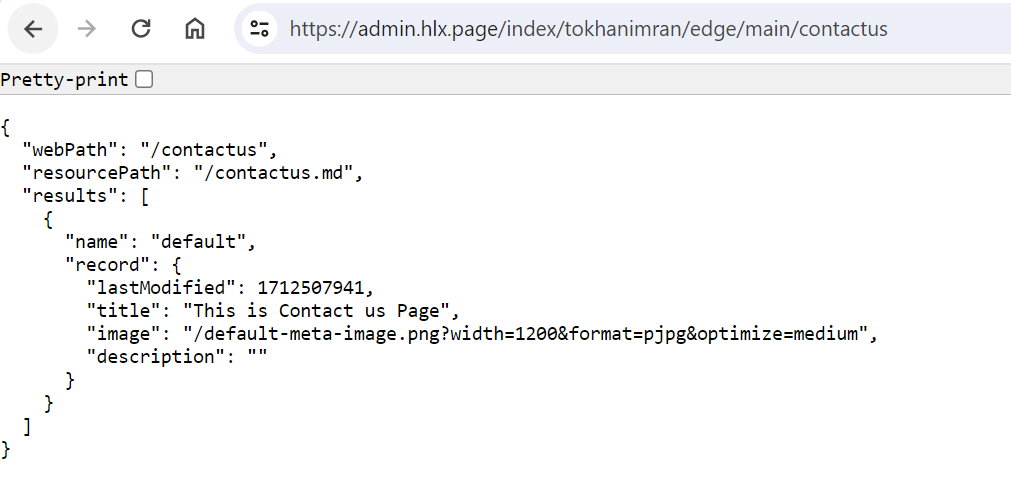
The Admin Service has an API endpoint where we can check the index representation of our page. Given our GitHub owner, repository, branch and owner, and a resource path to a page, its endpoint is:
We will be seeing below JSON response where the data node contains the index representation of the page. It is having same properties we defined ass part of query-index Google sheet above.
Special Scenarios for Robots
There are a few nuances on how pages get indexed by AEM in conjunction with indexing setup for our site. Let’s look at them:
In the following 2 situations, setting robots to noindex on the page metadata would not prevent it from being indexed by AEM:
- We have added a
robotscolumn inquery-index.xlsx - We have a
helix-query.yamlin our Github repository i.e. we have defined a custom index definition.
Recommendations
- If you do not have a custom index definition, it is recommended to not add a
robotscolumn to your index sheet unless you have a requirement for doing so.
Addingrobotscolumn to your index sheet would cause a page to be indexed by AEM even though it may haverobotsmetadata set tonoindex. - If you do have a custom index definition, pages would get indexed by AEM irrespective of setting
robotstonoindexon the page metadata. If you want to prevent this from happening, you can use spreadsheet filters to omit pages from index that haverobotsmetadata set tonoindex. For more details, see the section titled “Enforcingnoindexconfiguration with custom index definitions” below.
Enforcing “noindex” configuration with custom index definitions
If you have defined your own custom index definitions in helix-query.yaml, setting the robots property to noindex is not effective in preventing the pages from getting indexed. In order to enforce noindex configuration is such situations, do the following:
- Create a sheet named “
helix-default” in yourquery-index.xlsx. After this, yourquery-index.xlsxspreadsheet should have 2 sheets“raw_index” and“helix-default”. The“raw_index” sheet is there to have all the raw indexed data. - Modify your custom
helix-query.yaml(it must be in your project’s Github repository) and add therobotsproperty so that it gets indexed. - Now set up your
“helix-default” sheet in thequery-index.xlsxspreadsheet to get automatically filled up using Excel formula which ensures that all the rows inraw_indexwhich haverobotsproperty set asnoindex, do not get copied over to thehelix-defaultsheet. This can be done by using an Excel formula like this=FILTER(Table1,NOT(Table1[robots]="noindex")) - Now your helix-default sheet has only the rows from
raw_indexthat do not haverobotsproperty set tonoindex. - Ensure that you publish the pages that you want to get indexed.
- Now if you fetch the index as usual like:
https://<branch>--<repo>-<org>.hlx.page/query-index.json, you’d only get data fromhelix-defaultsheet i.e. entries that are not explicitly prevented from getting indexed through therobotproperty set asnoindex.
Reference: https://experienceleague.adobe.com/en/docs/experience-manager-edge-delivery/using/build/indexing

Imran Khan, Adobe Community Advisor, certified AEM developer and Java Geek, is an experienced AEM developer with over 12 years of expertise in designing and implementing robust web applications. He leverages Adobe Experience Manager, Analytics, and Target to create dynamic digital experiences. Imran possesses extensive expertise in J2EE, Sightly, Struts 2.0, Spring, Hibernate, JPA, React, HTML, jQuery, and JavaScript.